DBのトランザクション分離レベル
目次
トランザクション分離レベルとは
DBにおいて、複数のトランザクションが同時に実行された際に、相互に影響を与える度合いを示すものです。下記の通り、トランザクションが相互に影響を与えるケースがある為、許容可能なトランザクション分離レベルを選択する必要があります。
トランザクションが相互に影響を与える事象
値の更新時
- ダーティーリード: 別トランザクションがWRITEした、コミット前のデータをREADしてしまうこと。下図においては、
READ1とREAD2で結果が変わってしまう。 - 反復不能読み取り: 別トランザクションがWRITEした、コミット後のデータをREADしてしまうこと。下図においては、
READ2とREAD3で結果が変わってしまう。

レコードの追加時
- ファントムリード: 別トランザクションがCREATEした、コミット後のデータをREADしてしまうこと。下図においては、
READ1とREAD2で結果が変わってしまう。

トランザクション分離レベルの一覧
| 分離レベル | 説明 | 防止可能な事象 |
|---|---|---|
| READ UNCOMMITTED | コミットされていないデータを参照する可能性がある。 | - |
| READ COMMITTED | READ実行の直前までにコミットされたデータのみを参照する。 | ダーティーリード |
| REPEATABLE READ | トランザクション開始の直前までにコミットされたデータのみを参照する。 | 反復不能読み取り |
| SERIALIZABLE | 複数のトランザクションを逐次的に実行した結果が返却される。 | ファントムリード |
I/O処理の分類まとめ
I/O処理の分類
"I/O処理準備中の振る舞い"と" I/O処理完了の連携方法"の組み合わせにより、以下の通り分類されます。

"I/O処理準備中の振る舞い"
カーネルがI/O処理の準備中*1だった際の、アプリケーションの振る舞いで、以下の通り分かれます。
"I/O処理完了の連携方法"
カーネルがI/O処理を完了した際の、アプリケーションへの連携方法で、以下の通り分かれます。
同期I/O: アプリケーションからの問い合わせにより、処理完了を連携する。非同期I/O: カーネルからの通知により、処理完了を連携する。
I/O処理の分類毎のシーケンス
以下サイトの内容を元に、分類毎のシーケンスの違いを見てみましょう。
Boost application performance using asynchronous I/O – IBM Developer
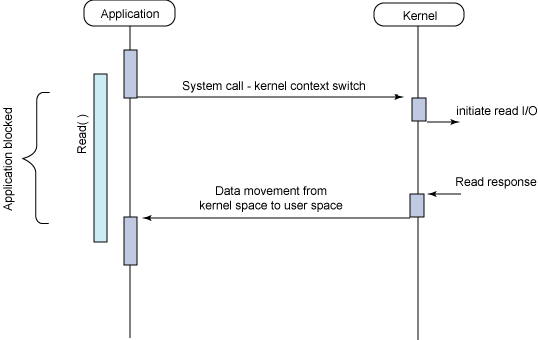
同期ブロッキングI/O
下図より、以下が伺えます。
ブロッキングI/O: カーネルのI/O処理の準備完了を(initiate read I/OからRead responseまで)、アプリケーションが待つ。同期I/O: I/O処理の完了(Read response)をアプリケーションが問い合わせる。
同期ノンブロッキングI/O
下図より、以下が伺えます。
ノンブロッキングI/O: カーネルのI/O処理の準備完了を、アプリケーションが待たない。同期I/O: I/O処理の完了をアプリケーションが問い合わせる。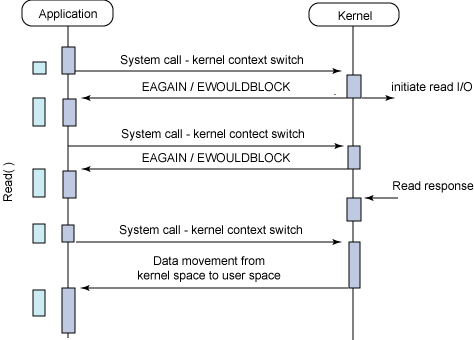
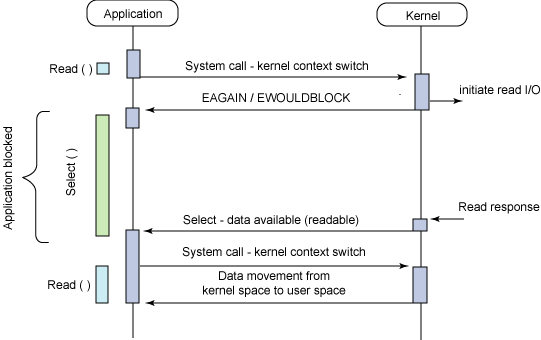
非同期ブロッキングI/O
下図より、以下が伺えます。
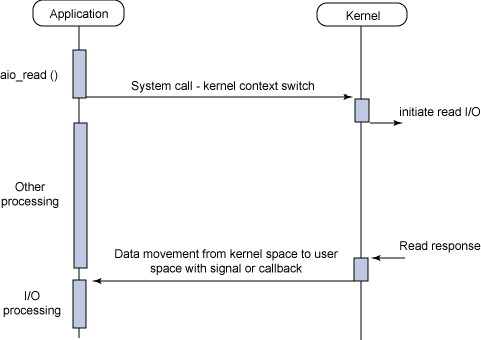
非同期ノンブロッキングI/O
下図より、以下が伺えます。
*1:ソケット送信バッファに空きがない場合や、ソケット受信バッファにデータがない場合
Java NIOを用てスケーラブルI/Oを実現する
目次
背景
先日、こちら記事でスケーラブルI/Oの実現方法を調査しました。結果として、1つのスレッドで複数のI/Oを管理することが必要であり、その実現に以下が必要だと分かりました。
- ノンブロッキングI/O
- I/Oの多重化
今回は、上記をJavaで実現する方法を調査します。Java NIOを用いたサンプル実装に関して、後日公開を行う予定です。
ノンブロッキングI/Oの実装方法
ストリームI/OはノンブロッキングI/Oに対応してない為、今回はNIO(New IO)を用いた実装を行います。
NIOとストリームI/Oの比較
従来のストリームI/Oでは、入出力先とのデータパスを、ストリームオブジェクトとして表現しています。そして、それらをつなぎ合わせることで、以下の様にバッファリングやデータ変換機能を追加します。
Socket socket = new Socket("localhost", 8080); InputStream inputStream = socket.getInputStream(); // バッファリング機能の追加 InputStream bufferedInputStream = new BufferedInputStream(inputStream); // プリミティブ型へのデータ変換機能の追加 DataInputStream dataInputStream = new DataInputStream(bufferedInputStream);
一方、NIOでは、以下の通りオブジェクト毎に役割が分担されています。
Channel: 入出力先とのデータパスを表すオブジェクトです。Buffer: バッファリングとデータ変換機能を提供するオブジェクトです。
両者の関係は下図の通りです。

Bufferクラス
Bufferクラスに関して、仕組みが複雑である為、以下に大まかな仕様をまとめます。
概要
Bufferは、ある1つの種類のプリミティブ型を格納可能なオブジェクトです。要素の取り込み, 取り出しの2つの用途に使用可能です。
主な属性
capacity:Bufferに格納可能な要素数の上限を表します。position: 要素の取り込み, 取り出しの開始位置を表します。limit: 要素の取り込み, 取り出しが行えない範囲の先頭の位置を表します。
主な操作
putメソッド:Bufferへ要素の取り込みを行うメソッドです。getメソッド:Bufferから要素の取り出しを行うメソッドです。flipメソッド:Bufferの属性であるpositionとlimitを、下図の通り"取り込み時の値"と"取り出し時の値"に相互に切り替えを行うメソッドです。
compactメソッド: 下図の通り、以下2つの操作を行うメソッドです。- 既に取り出した要素を捨て、残っている要素を
Bufferの先頭に移動する。 Bufferの属性であるpositionとlimitを、"取り出し時の値"から"取り込み時の値に"に切り替える。

- 既に取り出した要素を捨て、残っている要素を
I/Oの多重化の実装方法
利用するクラス一覧
以下、3つのクラスを利用します。
SelectableChannel:Selectorに対応したChannelを表すクラスです。SelectionKey:SelectableChannelをSelectorに登録した際の戻り値であり、両者のひも付きを表すクラスです。Selector: 目的の状態になったChannelを取得する為のクラスです。
これらのクラスの関係は、下図の通りです。SelectableChannelを複数のSelectorに登録可能であり、登録毎にSelectionKeyが発行されます。

Selectorを介して、目的の状態を満たしたSelectableChannelを取得することで、1つのスレッドで複数の接続が管理可能になります。
SelectableChannelをSelectorに登録する方法
SelectableChannelクラスのregisterメソッドを用いて、以下の通りSelectorにSelectableChannelを登録します。
selectableChannel.register(selector, SelectionKey.OP_xxx);
第2引数として、目的の状態を表すのビットパターンの集合を渡します。該当のビットパターンに関して、SelectionKeyにおいて、以下の通り定義されています。
public static final int OP_READ = 1 << 0; // 00001 public static final int OP_WRITE = 1 << 2; // 00100 public static final int OP_CONNECT = 1 << 3; // 01000 public static final int OP_ACCEPT = 1 << 4; // 10000
目的の状態を複数登録する場合は、以下の通り行います。(|はOR演算子です。)
selectableChannel.register(selector,
SelectionKey.OP_READ | SelectionKey.OP_WRITE); // 101
NginxでHTTPS対応のフォワードプロキシを構築
今回の記事の構成は、以下の通りです。構築方法は、「ハンズオン」に記載しています。
背景
フォワードプロキシとしてNginxの利用を検討しているのですが、HTTPSの通信を行った際に以下のエラーが発生しました。
$ curl --proxy http://localhost:80 https://www.google.com/ curl: (56) Received HTTP code 400 from proxy after CONNECT
調査の結果、NginxをHTTPS対応のフォワードプロキシとして利用する場合、別途パッチを当てる必要があるようです。その対応を行う際に、調べた内容を以下にまとめます。
調査結果
CONNECTとはなにか
上述のエラーメッセージに含まれるCONNECTに関して、HTTPのメソッドの1つになります。CONNECTメソッドを用いると、フォワードプロキシが通信内容を意識せずに、クライアントとサーバ間の中継を行う様になります。具体的な通信の流れは以下を御覧ください。
CONNECTメソッドを用いたHTTPS通信の流れ
How to Use NGINX as an HTTPS Forward Proxy Server - Alibaba Cloud Communityより

以下の流れで通信が行われます。
(a). クライアントがフォワードプロキシにCONNECTリクエストを行う。
(b)-(c). フォワードプロキシが目的のサーバへのTCPコネクションを確立する。
(d). フォワードプロキシがクライアントへ200 OKを返却する。
(e). フォワードプロキシが、クライアントとサーバ間のHTTPS通信をそのまま中継する。
そもそも、なぜCONNECTメソッドが必要か
HTTPSでは、HTTPの通信内容がSSLによって暗号化されています。その為、フォワードプロキシは通信内容を把握できず、送信先のサーバも知ることができません。
そこで上述の流れの通り、CONNECTメソッドを用いることで、フォワードプロキシが通信内容を把握できずとも、クライアントとサーバ間の通信が可能になります。
エラー原因
今回のエラーに関して、NginxがCONNECTメソッドに対応していないことが、発生の原因になります。
ハンズオン
概要
Nginxに以下パッチを適用し、CONNECTメソッドを使用可能にします。
GitHub - chobits/ngx_http_proxy_connect_module: A forward proxy module for CONNECT request handling
下記の「手順」では、Dockerを用いてCentOSのコンテナ上で、Nginxのソースコードを取得し、該当のパッチを適用し、動作確認を行うまでを記載しています。
手順
Nginxのソースコードを取得
$ docker run -it centos:centos7 /bin/bash // 以降、CentOSのコンテナ内での操作 $ cd /var/tmp $ yum install -y wget $ wget http://nginx.org/download/nginx-1.9.2.tar.gz $ tar -xzvf nginx-1.9.2.tar.gz
パッチを取得し適用
$ yum install -y git $ git clone https://github.com/chobits/ngx_http_proxy_connect_module.git $ yum install -y patch $ cd nginx-1.9.2/ // patchコマンドを発行し、diffファイル(proxy_connect.patch)の内容を元に、ソースコードの書き換えを行う。 $ patch -p1 < /var/tmp/ngx_http_proxy_connect_module/patch/proxy_connect.patch
ソースコードをコンパイルし起動
$ yum install -y gcc pcre pcre-devel openssl openssl-devel gd gd-devel $ ./configure --add-module=/var/tmp/ngx_http_proxy_connect_module $ make && make install $ alias nginx=/usr/local/nginx/sbin/nginx $ nginx
設定ファイルを修正し反映
/usr/local/nginx/conf/nginx.confファイルのserverコンテキスト内の記載を、以下の通り追記・変更する。
...
http {
...
server {
listen 80;
server_name localhost;
# ↓追記箇所
resolver 8.8.8.8; # DNSサーバのIPアドレス
proxy_connect;
# ↑追記箇所
...
location / {
# ↓変更箇所(既存の記述は削除)
proxy_pass $scheme://$http_host$request_uri;
# ↑変更箇所
}
...
}
}
...
その他の設定に関して、以下URIの「Directive」を御覧ください。
GitHub - chobits/ngx_http_proxy_connect_module: A forward proxy module for CONNECT request handling
設定の反映の為に以下コマンドを発行します。
$ nginx -s reload
動作確認
以下の通り、フォワードプロキシ経由でHTTPS通信を行った際に、結果が無事取得できることが確認できます。
$ curl --proxy http://localhost:80 https://www.google.com <!doctype html><html itemscope=...
CircleCIでタグ発行を契機にサーバへデプロイ
やりたいこと
先日、以下の記事でCircleCIの導入を行いました。今回は、バージョン番号のタグ発行を契機とした、サーバへのデプロイを自動化します。
CircleCIの調査 - Anarchy In the 1K
事前準備
SSH
SSHキーの作成
CircleCIがサーバに接続する為のSSHキーを、任意の端末上で以下の通り作成します。
$ssh-keygen -m pem Generating public/private rsa key pair. Enter file in which to save the key (・・・/.ssh/id_rsa): <出力先のフォルダ名/ファイル名> Enter passphrase (empty for no passphrase): //何も入力せずEnter Enter same passphrase again: //何も入力せずEnter
サーバに公開鍵の登録
上記で作成した鍵のうち、公開鍵(拡張子がpub)を以下の通りサーバに登録します。
ssh-copy-id <SSH接続するサーバのユーザ名>@<SSH接続するサーバのホスト名> -i <パブリックキーのパス>
CircleCIに秘密鍵の登録
以下ページの「追加手順」に従い、秘密鍵をCircleCIに登録します。
CircleCI に SSH 鍵を登録する - CircleCI
5.Private Key には、登録したい SSH 鍵の文字列を貼り付けます
上記に関しては、以下コマンドで出力された内容をコピーして貼り付けます。
cat <秘密鍵のパス>
また、後ほど必要となる為、登録完了後の画面に表示される、Fingerprintの値を控えておいて下さい。
環境変数の定義
下記の通り、人に知られたくない情報は、.circleci/config.ymlに記載するのではなく、プロジェクト設定より環境変数として定義するのが良い様です。
環境変数の使い方 - CircleCIより
.circleci/config.yml ファイルでは隠したい環境変数を宣言しないようにしてください。そのプロジェクトにアクセスできるエンジニア全員が config.yml ファイルの全文を見ることができます。 隠したい環境変数は CircleCI のプロジェクト設定やContexts設定で登録するようにしてください。
そこで、Project Settings > Environment Variables > Add Environment Variableで、以下の通り環境変数*1を定義します。
| Name | Value |
|---|---|
| USER_NAME | <SSH接続するサーバのユーザ名> |
| HOST_NAME | <SSH接続するサーバのホスト名> |
.circleci/config.ymlの設定
記載例
version: 2.1
jobs:
build:
machine:
image: circleci/classic:edge
steps:
- checkout
# 以下でbuild処理を行う。
- run: <command01>
- run: <command02>
...
deploy:
machine:
image: circleci/classic:edge
steps:
- add_ssh_keys # (1)
fingerprints:
- <上述の「CircleCIにプライベートキーの登録」で控えたFingerprintの値>
- run: ssh-keyscan ${HOST_NAME} >> ~/.ssh/known_hosts # (2)
- run: |
ssh ${USER_NAME}@${HOST_NAME} \<< EOF # (3)
# 以下でdeploy処理を行う。
<command01>
<command02>
...
EOF
workflows:
version: 2.1
build_and_deploy:
jobs:
- build:
filters:
tags: # (4)
only: /.*/
- deploy:
requires:
- build
filters:
tags: # (4)
only: /^v[0-9]+(\.[0-9]+)*/
branches: # (5)
ignore: /.*/
解説
コンテナに対して、秘密鍵を登録する。(1)
known_hostsを作成する。(2)
該当のコマンドで、接続先の公開鍵のフィンガープリントをknown_hostsに記録します。
サーバにSSHで接続する。(3)
上述の「環境変数の定義」で登録した値を用いて、サーバにSSH接続を行います。例では、ヒアドキュメントを用いており、EOFまでのコマンドがサーバ上で実行されます。
<<に関して、バックスラッシュでエスケープする必要があります。(地味にハマりました。)
job実行の条件にタグ発行を追加する。(4)
ジョブの実行を Workflow で制御する - CircleCIより
CircleCI は明示的にタグフィルターを指定しない限り、 タグが含まれる Workflows は実行しません。
上記に記載がある通り、タグ発行を契機としたjobの実行に関して、明示的に設定を行う必要があります。
buildjobに関して、only: /.*/とすることで、全てのタグ発行を契機に、該当jobを実行する様にしています。
一方でdeployjobに関して、only: /^v[0-9]+(\.[0-9]+)*/とすることで、バージョン番号のタグ発行を契機に、該当jobを実行する様にしています。
job実行の条件からブランチの更新を除く。(5)
タグ発行を契機にしたjob実行に関して、明示的な設定が必要だったのに対して、ブランチの更新を契機にしたjob実行に関して、デフォルトで有効となっています。
deployjobに関して、バージョン番号のタグ発行時のみ実行したい為、ignore: /.*/とすることで、ブランチの更新を契機に実行しない様にしています。
CircleCIの導入
CircleCIとは
GitHub上のリポジトリの更新を契機として、処理実行が可能なCI/CDサービスです。リポジトリ上のに配置した.circleci/config.ymlに則り、CircleCIが処理を行います。CircleCIの概要に関しては、合わせて以下もご覧下さい。
継続的インテグレーションのプロダクトと機能 - CircleCI
使用した際の所感としては、SaaS型でJenkinsの様に自前でサーバを立てる必要がなく、手軽に導入できるのがとても良かったです。
導入手順
以下URIよりCircleCIのSign upを行います。その際に、
Sign up with GitHubを選択し、GitHubとの紐付けを行います。
Signup - CircleCI下図の通り、
Set Up Projectボタンを押下し、既存のリポジトリをCircleCIに紐付けます。

下図の通り、
Start Buildingボタンを押下し、続いてAdd Configボタンを押下します。 すると、該当のリポジトリに.circleci/config.ymlファイルが追加された、circleci-project-setupブランチが作成されます。


CIrcleCIがリポジトリの更新を検知し、
.circleci/config.ymlに則った処理を実行します。成功すると下図の通り、STATUSがSUCCESSになります。

ハンズオン
設定ファイルの変更
上述の導入手順で追加した.circleci/config.ymlを、下図の通りGitHub上で直接編集します。

以下をコピペしcommit changesボタンを押下して下さい。
version: 2.1
jobs: # ジョブ
job01:
docker: # Executor
- image: buildpack-deps:trusty
steps: # ステップ
- run: echo "job01"
job02:
docker:
- image: buildpack-deps:trusty
steps:
- run: echo "job02"
workflows: # ワークフロー
version: 2.1
workflow01:
jobs:
- job01
- job02:
requires:
- job01
結果確認
CIrcleCIがリポジトリの更新を検知し、
workflow01が実行さた様子が確認できます。
workflow01を押下すると、job01,job02の順にジョブが実行さた様子が確認できます。
job01を押下すると、ステップが実行さた様子が確認できます。

解説
用語整理
ステップ, ジョブ, ワークフロー
上記に関して、それぞれ下図の関係になります。

- ステップ: シェルコマンドなどの、実行可能な1つの処理を指します。
- ジョブ: ステップの集まりを指します。依存関係が無いジョブは、有料プランでは並列で実行されます。
- ワークフロー: ジョブの集まりを指します。ジョブの実行に関する制御を行います。
合わせて以下もご覧下さい。
Orbs、ジョブ、ステップ、ワークフロー - CircleCI
Executor
ジョブ毎の処理を実行する環境を指します。以下より選択が可能です。
- docker
- machine
- macos(有料プランのみ)
合わせて以下もご覧下さい。
Executor とイメージ - CircleCI
Executor タイプの選び方 - CircleCI
設定ファイル詳細
ステップ
シェルコマンドの実行
以下の通り、run: <コマンド>という記載をすることで、実行が可能です。
steps: # ステップ - run: echo "job01"
ジョブ
Executorの指定
以下の通り、dockerを指定しています。使用するイメージに関して、- image: <イメージ名>で指定可能です。
job01:
docker: # Executor
- image: buildpack-deps:trusty
指定可能なイメージに関して、以下をご覧ください。
Pre-Built CircleCI Docker Images - CircleCI
ワークフロー
ジョブの実行順序の制御
以下の通り、requires:を記載することで、ジョブの依存関係を指定可能です。
- job02:
requires:
- job01
Gradleでマルチプロジェクト
マルチプロジェクトについて
マルチプロジェクトとは
複数の子プロジェクトを内部に保持するプロジェクトのことを指します。マルチプロジェクトを用いることで、1つのプロジェクトを更に細かい粒度で分割することが可能になります。
マルチプロジェクトの使い所
以下参考サイトを見ると、リリースタイミングが同じプロジェクトをマルチプロジェクトとして管理するのが良い様です。
つまり、変更理由が同じプロジェクトは、マルチプロジェクトとして1つにまとめる。一方で、変更理由が異なるプロジェクトは、個別プロジェクトとして扱う。ということになるかと思います。
参考サイト
https://discuss.gradle.org/t/multiproject-vs-composite-what-to-choose/20581/2
If two things have the same version and release cycle, then they should be in a multi-project build. If they are independent of each other, they should be in independent builds.
gradle - Do composite builds make multi-module builds obsolete? - Stack Overflow
In my opinion, a multi-module build is a single system which is built and released together. Every module in the build should have the same version and is likely developed by the same team and committed to a single repository (git/svn etc).
実装例
以下サイトを元に実装を行います。
Spring Boot 入門 | マルチモジュールプロジェクトの作成 - コードサンプル
完成版のコードに関して、以下に配置しています。
GitHub - U0326/code-example-gradle-multi-project
実装手順
libraryとそれを呼び出すapplicationを小プロジェクトとして持つ、親プロジェクトを以下手順で作成します。
親プロジェクトの作成
任意の場所で、以下コマンドを発行します。
mkdir multi_module cd multi_module touch settings.gradle
上記で作成したsettings.gradleに、以下内容を記載します。include()でマルチプロジェクトに含める子プロジェクトを指定します。
rootProject.name = 'gs-multi-module' include 'library' include 'application'
libraryプロジェクトの作成
https://start.spring.io
上記サイトで下図の通り入力を行い、ベースとなるプロジェクトを作成します。

作成したlibraryフォルダをmulti_moduleフォルダに配置し、以下コマンドを発行します。
cd "multi_moduleフォルダのパス" cd library mv gradlew* gradle .. rm -rf src/main/java/com/example/multimodule/library rm -rf src/test/java/com/example/multimodule/library mkdir src/main/java/com/example/multimodule/service
libraryの実行可能jarを生成させない為に、libraryフォルダ内のbuild.gradleに以下内容を追記します。
bootJar {
enabled = false
}
jar {
enabled = true
}
./src/main/java/com/example/multimodule/service配下に以下Javaソースを配置します。
package com.example.multimodule.service; import org.springframework.boot.context.properties.EnableConfigurationProperties; import org.springframework.stereotype.Service; @Service @EnableConfigurationProperties(ServiceProperties.class) public class MyService { private final ServiceProperties serviceProperties; public MyService(ServiceProperties serviceProperties) { this.serviceProperties = serviceProperties; } public String message() { return this.serviceProperties.getMessage(); } }
package com.example.multimodule.service; import org.springframework.boot.context.properties.ConfigurationProperties; @ConfigurationProperties("service") public class ServiceProperties { /** * A message for the service. */ private String message; public String getMessage() { return message; } public void setMessage(String message) { this.message = message; } }
applicationプロジェクトの作成
https://start.spring.io
上記サイトで下図の通り入力を行い、ベースとなるプロジェクトを作成します。

作成したapplicationフォルダをmulti_moduleフォルダに配置し、以下コマンドを発行します。
cd "multi_moduleフォルダのパス" cd application rm -rf gradlew* gradle rm src/main/java/com/example/multimodule/application/Application.java touch src/main/resources/application.properties
上記で作成したapplication.propertiesに以下内容を記載します。
service.message=Hello, World
applicationフォルダ内のbuild.gradleのdependencies内に以下内容を追記します。project()を用いて、マルチプロジェクト内の別プロジェクトを参照します。
implementation project(':library')
./src/main/java/com/example/multimodule/application配下に以下Javaソースを配置します。
package com.example.multimodule.application; import com.example.multimodule.service.MyService; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @SpringBootApplication(scanBasePackages = "com.example.multimodule") @RestController public class DemoApplication { private final MyService myService; public DemoApplication(MyService myService) { this.myService = myService; } @GetMapping("/") public String home() { return myService.message(); } public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } }
実行結果
以下の通り親プロジェクト上でコマンドを一括で発行します。
cd "multi_moduleフォルダのパス" ./gradlew build ./gradlew :application:bootRun
http://localhost:8080にアクセスすると以下画面が表示されます。
